Monte Carlo Method¶
We use Monte Carlo method to “fake” a system that obays a specific distribution so that we could use it as samples of such a distribution.
Why Not Just Randomly Sample from All States¶
In statistics, the curse of dimensionality has been haunting us. In Ising model, the number of dimension is the number of spins. In such a high dimensional system, sampling the representative states requires a huge sample.
Curse of Dimensionality: Volume of 20D Ball
It can be shown with a simple random sampling method to calcuate the volume of a 20 dimensional ball of unit length diameter.
To calculate the volume of this 20D ball, we construct a 20D box that contains the ball. Then we place random points in the box. Suppose we have \(N_b\) points out of \(N\) points falling inside the ball, the volume of the ball can be approximated by \(N_b/N\).
It may sound simple. However, one would realize that a good approximation requires a huge amount of sample points.
For our Ising model, randomly sampling the states means we are have a very high temperature that the probability of all enegy states are of no difference. Instead of such random sampling, we could make use of our theoretical knowledge of the Boltzman distribution and sample according to the Boltzman distribution, which is importance sampling in statistics.
Metropolis Algorithm for Ising Model¶
To solve the classical Ising model on a 2D grid, we would like to force the system to stay close to the Boltzman distribution,
where \(E\) is the energy and \(Z\) is the partition function.
On a 2D grid, the energy \(E\) of all the spin is determined by the configuration of the spins (the microstates) \(\mathscr M\), i.e., \(E = E(\mathscr M)\).
Given all the possible configurations of Ising model, we calculate observable in the following way,
For a Ising model with \(N\) spins, we have \(2^N\) possible configurations for the spins. It quickly becomes an impossible mission as the number of spins increases.
In statistics, we could estimate the average of quantities using sampling methods. There is no need to exhaust the whole population. W randomly choose some configurations, \(\{\mathscr M_i\}\) and calculate the observables using this sample.
Importance Sampling
There is always a catch. We also have the curse of high dimensions. Random sampling becomes inefficient in high dimensions. To achive a reasonably good result, we have to sample a huge amount of configurations. To solve this problem, the glory importance sampling was invented.
In Monte Carlo method, we will generate some configurations and use those configurations to calculate our ensemble average of observables.
State Transitions and Markov Chain¶
To simulate the system, we will construct a series of history independent transitions between the states,
We will use a lowest order approximation and require the transition probability \(P(\sigma_{i+1} \vert \sigma_i)\) to the next state \(\sigma_i\) only depends on the current state \(\sigma_{i+1}\).
Imagine we force a rule upon the transition probabilities, the states will be close to a path that is defined by the rule. This rule shall be the Boltzman distribution.
Metropolis Algorithm¶
Metropolis algorithm is a Monte Carlo method for sampling. We will calculate the energy \(\langle E \rangle\) and magnetization \(\langle M \rangle\) of the equilibrium Ising model. The specific heat and magnetic susceptibility can be calculated using the energy and magnetization.
To demonstrate the algorithm, we use a 2D N by N lattice of magnetic spins.
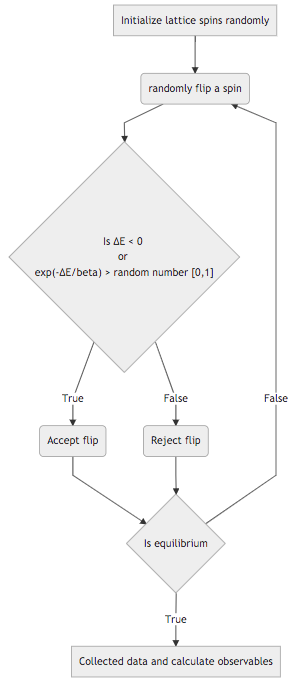
Fig. 18 Metropolis algorithm
Flowchart Code
graph TD
A[Initialize lattice spins randomly] --> B(randomly flip a spin)
B --> C{"Is ∆E < 0 <br> or <br> exp(-∆E/beta) > random number [0,1]" }
C -->|True| D(Accept flip)
C -->|False| F(Reject flip)
D --> J{"Is equilibrium"}
F --> J{"Is equilibrium"}
J --> |False| B
J --> |True| K["Collected data and calculate observables"]
This GitHub repository is my working example of this algorithm for Ising model.